5. Basic program structure
For this course, a basic program structure is provided which predefines all required functions to solve the data analysis task.
The main() function includes predefined function calls related to the different sections of this course.
It also includes tests to automatically validate the function implementations.
Todo
Open the analysis.py file and check the main() function.
It contains the outline of this course and is structured accordingly.
It looks complicated, however most of it are associated tests.
Look for instance at assert df is not None.
This line raises an AssertionError if the variable df is None.
The testing provides you with a direct feedback and lets you know if your implemented functions work as expected.
Warning
Please only change the main() function when instructed during this course (indicated by the term FIXME).
All new program code should be added to the other predefined functions.
Hint
The predefined function contain documentation explaining how the function should work. Additionally, hints are provided to help you implement the functions. For every hint usually just a few lines of code need to be written. You should use the hints to comment your code. Feel free to find your own solution if you don’t want to follow the hints.
6. Data preparation - Work data
In a first step, the obtained work data files should be merged into one dataframe.
Therefore, the function get_dataframe_from_directory should be implemented.
Todo
Expand the get_dataframe_from_directory function to load all work data files and put them in one dataframe.
Ensure that the timestamp is in the Pandas datetime format and use the timestamp as index and sort your data according to it using sort_index().
Remove all columns containing “Unnamed”.
Todo
Check if the created dataframe gets validated successfully and if the dataframe has the correct shape.
In a second step, sensor-based picking errors should be removed from the user data analysis.
Todo
Implement the mask_dataframe function to remove:
all rows that contain “RemoveItem” in column “ActionName”
all columns that contain “pickItem” in row “ActionType” only if row “Error” is True.
Todo
Check if the adjusted dataframe gets validated successfully and if the dataframe has the correct shape.
6.1. Base value calculation
Based on the obtained work data, the following information should be calculated for further analysis:
Cycle times per user and run
Mean times per user action (e.g. mean times for action “pickItem” for object “Nut”) as setpoints for production planning
6.1.1. Cycle times
The cycle times (run times) allow an analysis regarding the individual user performance. Also, it can be analyzed if the user performance increases with the run numbers.
Todo
Implement the calculate_cycle_times function.
Create a new dataframe which includes all single cycle times per user and run number.
As the timestamps still include the removed actions, please use the DeltaTime
values for your cycle time calculation.
Todo
To create a better overview for the data analysis, calculate the following information and put them in the predefined dictionary:
minimum cycle time (seconds) for all runs of all users
average cycle time (seconds) for all runs of all users
maximum cycle time (seconds) for the last run of each user
average cycle time (seconds) for the last run of each
As the timestamps still include the removed actions, please use the DeltaTime
values for your cycle time calculation.
6.1.2. Setpoints
The obtained data should be used to set new default times (setpoints) for future handgrip assembly actions at the MWS. For instance, the default times are required to provide individual feedback to each user regarding his performance and improvements.
As the mounting actions vary in effort and dexterity, individual default times for each action are required instead of general default times per action type.
Todo
Implement the calculate_setpoints function to calculate the average working time per
user activity and store them in a csv file for further usage.
The average working times should be specified according to “ActionType” and “Node”.
Also, return the setpoints as a multiindex pandas series.
7. OEE calculation
The overall equipment effectiveness is one of the main process indicators for production environments. It is calculated for production resources (e.g., a manual work station) for specific time intervals (e.g., days). It is not used to compare the effectiveness of different production resources but to analyze the effectiveness of one specific resource.
The typical OEE calculation is based on the three OEE Factors: Availability ( ),
Performance (
),
Performance ( ), and Quality (
), and Quality (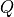 ).
).
In general, there exist different possibilities on how to calculate the OEE parameters. Typical examples are shown below.

For the availability (), the real production time (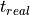 ) is compared to the planned production time (
) is compared to the planned production time (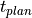 ). For instance, a workstation was planned to be operated 6 hours during an 8 hour shift; however, it was only running for 3 hours due to unplanned circumstances. Thus, the availability of this time interval is 50%.
). For instance, a workstation was planned to be operated 6 hours during an 8 hour shift; however, it was only running for 3 hours due to unplanned circumstances. Thus, the availability of this time interval is 50%.
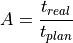
For the performance, the ideal production time (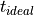 ) is calculated using the planned cycle time (
) is calculated using the planned cycle time (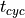 ) and the number of produced parts (
) and the number of produced parts ( ).
Next, the ideal production time () is compared to the real production time () for the produced parts. For instance, 100 parts were produced during the three hours (180 minutes) working time. According to the production planning, each part requires a planned cycle time of 1 minute. Thus, ideal production time was 100 minutes and the performance of this time interval 55.5%.
).
Next, the ideal production time () is compared to the real production time () for the produced parts. For instance, 100 parts were produced during the three hours (180 minutes) working time. According to the production planning, each part requires a planned cycle time of 1 minute. Thus, ideal production time was 100 minutes and the performance of this time interval 55.5%.
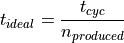
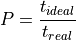
The quality is usually calculated by dividing the number of good parts ( ) by the number of total manufactured parts (
) by the number of total manufactured parts (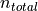 ). For instance, 90 parts were good parts and 10 parts got rejected. Thus, the quality was 90%.
). For instance, 90 parts were good parts and 10 parts got rejected. Thus, the quality was 90%.

Note
In this example of a handgrip assembly, the quality of the assembly routine is calculated instead
of focusing on finished assembly parts. Therefore, the number of correct production actions (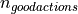 ) are compared to the total number of production actions (
) are compared to the total number of production actions (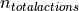 ).
).

In order to calculate the OEE indicators, the existing dataframe will be expanded.
7.1. Work information per day
The availability calculation for the obtained data set is a bit tricky as the work data was obtained in a user study with a fixed number of runs and not in a traditional shift system.
Therefore, the planned production time per day is accessed.
The planned starting times of each user slot can be found in the file planned_working_times.csv.
Todo
Adjust the function calculate_work_data() to create a new dataframe data with work information according to working days.
For the OEE indicator calculation and analysis, the following information is required per working day:
Number of timeslots (
TimeSlots)Number of users (
Users`)Number of user work actions (
Actions)Number of production steps with errors (
Errors)Number of produced parts (
ProducedParts)Real working time (
RealWorkingTime)Unused working time due to no-show participants (
UnusedWorkingTimes)
7.2. OEE parameters per day
As all required information have been obtained in the previous steps, the OEE parameters can be calculated per working day.
Todo
Adjust the calculate_oee() function to add the OEE parameters per day to the existing dataframe data.